pnpm
为什么用 pnpm
- 安装速度快 (非扁平包结构,不需要使用复杂的扁平算法)
- 节省磁盘空间(统一安装包到磁盘的某个位置,项目中的
node_modules通过硬链接链接到磁盘特定位置)
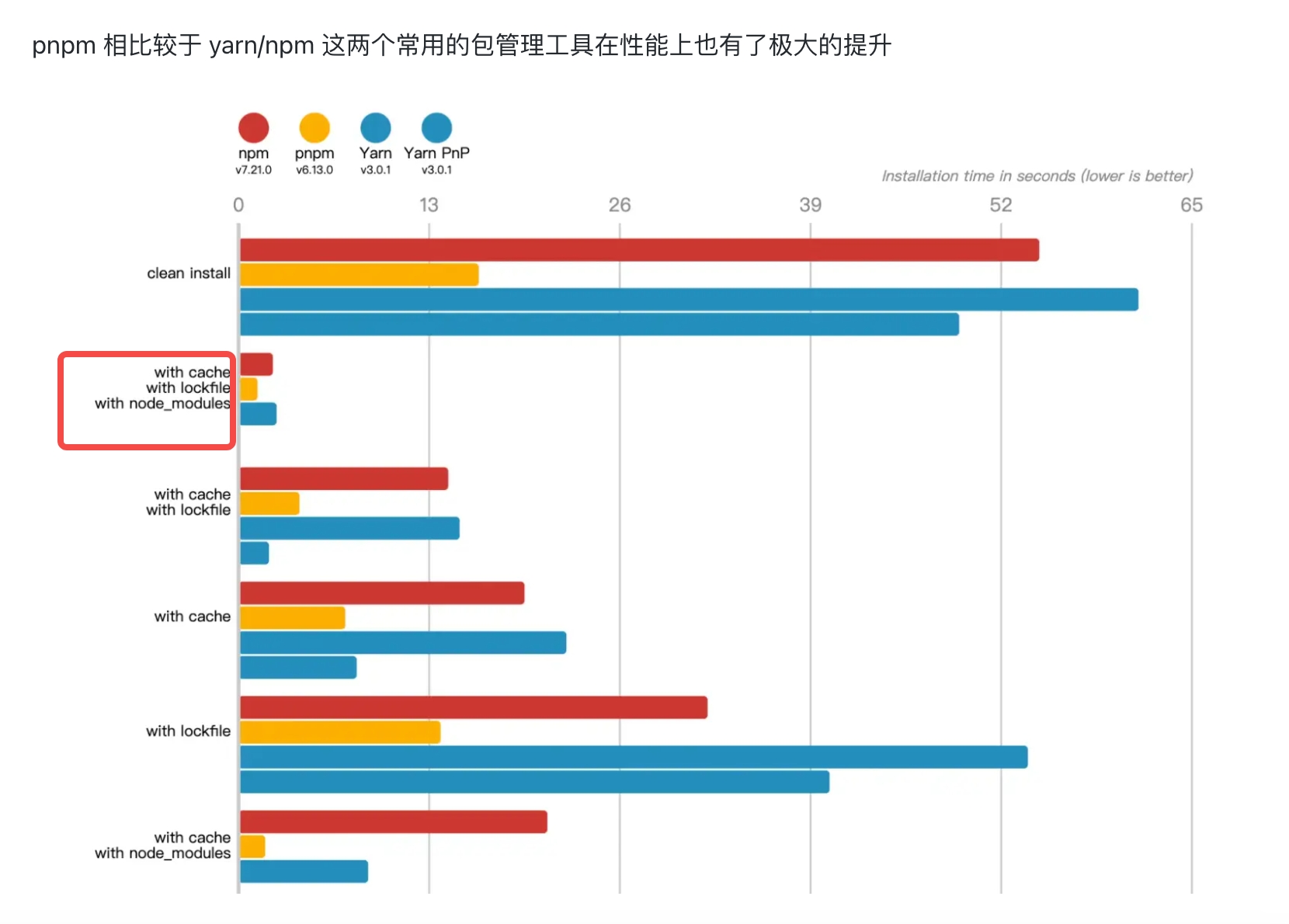
pnpm
npm3和yarn, 把所有依赖的依赖都扁平化提取到依赖同级, 通过锁定版本找到需要的依赖
但是有幽灵依赖的问题,比如说明明项目�里没有该依赖.但是依赖的依赖被提到了依赖里,于是可以引用到该依赖;
如果有一天依赖不用依赖的依赖, 那么你的引用就失效了
而且同一个依赖的多个版本不会同时被扁平化, 只有一个版本会被扁平化,其他的还是嵌套依赖,复制了很多次
pnpm 使用软链接, 依赖文件是个地址,链接到磁盘上一片全局仓库的空间, 不会路径过长和复制多次,通过软连接相互依赖
pnpm 解决幽灵依赖和嵌套名称过长问题(包隔离)
如果我们使用 yarn/npm 安装express,我们的node_modules目录会变成:
.png)
而如果使用 pnpm,会变成这样
.png)
node_modules 中只有一个叫 .pnpm 的文件夹以及一个叫做 express 的软链。 不错,pnpm 只安装了 express,所以它是唯一一个你的应用拥有访问权限的包。
但是 express 只是一个软链。express 的真实位置在node_modules/.pnpm/express@4.17.1/node_modules/express里,我们的.pnpm/ 以真正平铺的形式储存着所有的包,所以每个包(包括这个包的所有依赖包)都可以在这种命名模式的文件夹中被找到:.pnpm/<name>@<version>/node_modules/<name>
**这里的命名模�式是依赖包+版本+该包的 peerDep+版本
在这里面是真正的平铺,不会出现任何嵌套
为什么要隔离出express@4.17.1呢
这个node_modules中同时存有安装包express以及它的一些依赖包cookie等等
将安装包和依赖包放在express@4.17.1一起管理,防止依赖包通过 node 模块规则访问其他安装包express@3的依赖包, 即相互隔离
这个平铺的结构一方面避免了 npm v2 创建的嵌套 node_modules 引起的长路径问题,另一方面与 npm v3,4,5,6 或 yarn v1 创建的扁平的 node_modules 不同的是,它保留了包之间的相互隔离,解决了重复包的问题(幽灵依赖)。
pnpm 使用硬链接节省磁盘空间
那么 pnpm 是怎么做到如此大的提升的呢?是因为计算机里面一个叫做 Hard link 的机制,hard link 使得用户可以通过不同的路径引用方式去找到某个文件。pnpm 会在虚拟 store 里存储项目依赖的 hard links 。 hard links 可以理解为源文件的副本,项目里安装的其实是副本,它使得用户可以通过路径引用查找到源文件, 同时,不同的项目可以从虚拟 store 寻找到同一个依赖,大大地节省了磁盘空间。
hard links 指通过索引节点来进行连接。在 Linux 的文件系统中,保存在磁盘分区中的文��件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在 Linux 中,多个文件名指向同一索引节点是存在的。比如:A 是 B 的硬链接(A 和 B 都是文件名),则 A 的目录项中的 inode 节点号与 B 的目录项中的 inode 节点号相同,即一个 inode 节点对应两个不同的文件名,两个文件名指向同一个并不真实存在的文件,A 和 B 对文件系统来说是完全平等的。删除其中任何一个都不会影响另外一个的访问。
文件删除后再恢复内容,那么 hardlink 的 link 关系将不再维持,后续所有变更不会同步到 hardlink 里
Symbolic link
也叫软连接,可以理解为快捷方式,pnpm 可以通过它找到对应磁盘目录下的依赖地址。软链接文件只是其源文件的一个标记,当删除了源文件后,链接文件不能独立存在,虽然仍保留文件名,但却不能查看软链接文件的内容了
删除文件会影响 symlink 的内容,文件删除后再恢复内容,但是仍然会和 symlink 保持同步,链接文件甚至可以链接不存在的文件,这就产生一般称之为”断链”的现象 (我以为链接上去了,但是其实对应文件不存在)
pnpm 实现原理
包是从全局 store 硬连接到虚拟 store 的,这里的虚拟 store 就是 node_modules/.pnpm。 我们打开 node_modules 看一下:
.png)
.png)
确实不是扁平化的了,依赖了 solid-js,那 node_modules 下就只有 solid-js。 展开 .pnpm 看一下
.png)
所有的依赖都在这里铺平了,都是从全局 store 硬连接过来的,然后包和包之间的依赖关系是通过软链接组织的。 比如 .pnpm 下的 solid-js,这些都是软链接,
.png)
也就是说,所有的依赖都是从全局 store 硬连接到了 node_modules/.pnpm 下,然后之间通过软链接来相互依赖。 官方给了一张原理图,配合着看一下就明白了: .pnpm 内是嵌套结构打包扁平化
.png)
.pnpm 下都是依赖的依赖,任何依赖的依赖最终只有一份会硬链到全局 store 下,这一份真实的可以在很深的嵌套里,其他重复出现的依赖的依赖可能会在.pnpm 下找到能软链到的硬链依赖(一般是像黄色箭头往外软链)
直接依赖的软链也是链接到硬链依赖
所有软链都指向唯一一份的硬链依赖
软硬结合-优势之处
这套全新的机制设计地十分巧妙,不仅兼容 node 的依赖解析,同时也解决了:
-
幽灵依赖问题:只有直接依赖会平铺在 node_modules 下,子依赖(非直接依赖)不会被提升(通过软链接找到),bar1.0 也就不会找到 foo1.3(安装包)下的 bar1.1(依赖包),只会找到 bar1.0 下的硬链 bar1.0,不会产生幽灵依赖。(不过还是能找到 foo1.3 的安装包)
-
依赖分身问题:相同的依赖只会在全局 store 中安装一次。项目中的都是源文件的副本,几乎不占用任何空间,没有了依赖分身。节省磁盘空间,一个包全局只保存一份,剩下的都是软硬连接
软链接本身也几乎不会占用多少额外的存储空间,硬链接模式更是零额外内存空间占用,所以对于相同的包,pnpm 额外占用的存储空间可以约等于零。
硬链接
理解 pnpm 软硬链接的设计,首先要复习一下操作系统文件子系统对软硬链接的实现。
硬链接通过 ln originFilePath newFilePath 创建,如 ln ./my.txt ./hard.txt,这样创建出来的 hard.txt 文件与 my.txt 都指向同一个文件存储地址,因此无论修改哪个文件,都因为直接修改了原始地址的内容,导致这两个文件内容同时变化。进一步说,通过硬链接创建的 N 个文件都是等效的,通过 ls -li ./ 查看文件属性时,可以看到通过硬链接创建的两个文件拥有相同的 inode 索引:
ls -li ./
84976912 -rw-r--r-- 2 author staff 489 Jun 9 15:41 my.txt
84976912 -rw-r--r-- 2 author staff 489 Jun 9 15:41 hard.txt
其中第三个参数 2 表示该文件指向的存储地址有两个硬链接引用。硬链接如果要指向目录就麻烦多了,第一个问题是这样会导致文件的父目录有歧义,同时还要将所有子文件都创建硬链接,实现复杂度较高,因此 Linux 并没有提供这种能力
软链接
软链接通过 ln -s originFilePath newFilePath 创建,可以认为是指向文件地址指针的指针,即它本身拥有一个新的 inode 索引,但文件内容仅包含指向的文件路径
源文件被删除时,软链接也会失效,但硬链接不会,软链接可以对文件夹生效。
不足之处
-
全局 hardlink 也会导致一些问题,比如改�了 link 的代码,所有项目都受影响,比如对 postinstall 不友好,例如在 postinstall 里修改了代码,可能导致其他项目出问题,pnpm 默认就是 copy on write https://pnpm.io/npmrc#package-import-method ,但是 copy on write 这个配置对 mac 没生效——https://github.com/pnpm/pnpm/issues/2761,其实是 node 没支持导致的
-
由于 pnpm 创建的 node_modules 依赖软链接,因此在不支持软链接的环境中,无法使用 pnpm,比如 Electron 应用。
解决 Phantom dependencies
Phantom dependencies 被称之为幽灵依赖,解释起来很简单,即某个包没有被安装(package.json 中并没有,但是用户却能够引用到这个包) 这个现象的出现原理很好理解,在 npm 推出 v3 以后,一个库只要被其他库依赖,哪怕没有显式声明在 package.json 中,也可以会被安装在 node_modules 的一级目录里,我们可以“自由”的在项目中使用这些幽灵依赖
项目代码引用的某个包没有直接定义在 package.json 中,而是作为子依赖被某个包顺带安装了。代码里依赖幻影依赖的最大隐患是,对包的语义化控制不能穿透到其子包,也就是包 a@patch 的改动可能意味着其子依赖包 b@major 级别的 Break Change。
正因为这三层寻址的设计,使得第一层可以仅包含 package.json 定义的包,使 node_modules 不可能寻址到未定义在 package.json 中的包,自然就解决了幻影依赖的问题。
但还�有一种更难以解决的幻影依赖问题,即用户在 Monorepo 项目根目录安装了某个包,这个包可能被某个子 Package 内的代码寻址到,要彻底解决这个问题,需要配合使用 Rush,在工程上通过依赖问题检测来彻底解决。pnpm workspace 并不能解决这个问题,在子目录引用到了根目录的依赖, 不过这种引用会更容易定位。
试想这种 case:
node_modules
/a
/b
那么这里这个 b 就成了一个幽灵依赖,如果某天某个版本的 a 依赖不再依赖 b 或者 b 的版本发生了变化,那么 require b 的模块部分就会抛错
得益于 pnpm 的目录格式,它天生解�决了这个幽灵依赖问题,如果不显式声明,开发者不可能拥有 b 的使用权限
每个包(包括这个包的所有依赖包)都可以在这种命名模式的文件夹(通过目录限制权限)中被找到:.pnpm/<name>@<version>/node_modules/<name>
.png)
pnpm store prune 是如何判断缓存是否需要删除的
当硬链接引用计数为 1 时则代表该文件没有在其他项目中用到,则进行删除 Pnpm 源码中相关判断逻辑如下:
export default async function prune (storeDir: string) {
//....
if (stat.nlink === 1 || stat.nlink === BIG_ONE) { // 判断硬连接数量是否为1
await fs.unlink(filePath) // 删除文件
fileCounter++
removedHashes.add(ssri.fromHex(`${dir}${fileName}`, 'sha512').toString())
}
//....
}
Pnpm 清理缓存
可以使用 pnpm store prune 从全局 store 中删除未引用的包。运行 pnpm store prune 是无害的,对您的项目没有副作用。 如果以后的安装需要已经被删除的包,pnpm 将重新下载他们。最好的做法是 pnpm store prune 来清理存储,但不要太频繁。 有时,未引用的包会再次被需要。 这可能在切换分支和安装旧的依赖项时发生,在这种情况下,pnpm 需要重新��下载所有删除的包,会暂时减慢安装过程。
Pnpm 缺点
Pnpm 当前存在一定的兼容问题,在少数场景不可用。主要可能有以下两个原因。1、软链接本身在不同环境下存在一定兼容问题。2、部分 npm 包在进行软链接的之后会产生意料之外的 bug。
另一种形式的幽灵依赖
拓展
http://www.javashuo.com/article/p-tdfleods-ks.html https://juejin.cn/post/6844903601563762702 https://zhuanlan.zhihu.com/p/107343333 https://pnpm.io/zh/blog/2020/05/27/flat-node-modules-is-not-the-only-way
peerDependencies
如果项目依赖中有 react,就不会安装
否则还是会自动安装
如果版本不匹配,也不会安装
只看有没有,不看版本,因此问题很多
目的是提示宿主环境去安装满足 peerDependencies 所指定的依赖 在依赖包时,永远都是引用宿主环境统一安装的依赖包 最终解决插件依赖包不一致问题
pnpm 对 peer-dependences 有一套严格的安装规则。对于定义了 peer-dependences 的包来说,意味着为 peer-dependences 内容是敏感的,潜台词是说,对于不同的 peer-dependences,这个包可能拥有不同的表现,因此 pnpm 针对不同的 peer-dependences 环境,可能对同一个包创建多份拷贝。
比如包 bar peer-dependences 依赖了 baz^1.0.0 与 foo^1.0.0,那我们在 Monorepo 环境两个 Packages 下分别安装不同版本的包会如何呢?
- foo-parent-1
- bar@1.0.0
- baz@1.0.0
- foo@1.0.0
- foo-parent-2
- bar@1.0.0
- baz@1.1.0
- foo@1.0.0
node_modules
└── .pnpm
├── foo@1.0.0_bar@1.0.0+baz@1.0.0
│ └── node_modules
│ ├── foo
│ ├── bar -> ../../bar@1.0.0/node_modules/bar
│ ├── baz -> ../../baz@1.0.0/node_modules/baz
│ ├── qux -> ../../qux@1.0.0/node_modules/qux
│ └── plugh -> ../../plugh@1.0.0/node_modules/plugh
├── foo@1.0.0_bar@1.0.0+baz@1.1.0
│ └── node_modules
│ ├── foo
│ ├── bar -> ../../bar@1.0.0/node_modules/bar
│ ├── baz -> ../../baz@1.1.0/node_modules/baz
│ ├── qux -> ../../qux@1.0.0/node_modules/qux
│ └── plugh -> ../../plugh@1.0.0/node_modules/plugh
├── bar@1.0.0
├── baz@1.0.0 *
├── baz@1.1.0 **
├── qux@1.0.0
├── plugh@1.0.0
可以看到,安装了两个相同版本的 foo,虽然内容完全一样,但却分别拥有不同的名称!:
<foo@1.0.0_bar>@1.0.0+baz@1.0.0、<foo@1.0.0_bar>@1.0.0+baz@1.1.0
这也是 pnpm 规则严格的体现,任何包都不应该有全局副作用,或者考虑好单例实现,否则可能会被 pnpm 装多次。
全局安装目录 pnpm-store 的组织方式
硬链接目标文件并不是普通的 NPM 包源码,而是一个哈希文件,这种文件组织方式叫做 content-addressable(基于内容的寻址)。
简单来说,基于内容的寻址比基于文件名寻址的好处是,即便包版本升级了,也仅需存储改动 Diff,而不需要存储新版本的完整文件内容,在版本管理上进一步节约了存储空间。
pnpm-store 的组织方式大概是这样的:
~/.pnpm-store
- v3
- files
- 00
- e4e13870602ad2922bfc7..
- e99f6ffa679b846dfcbb1..
..
- 01
..
- ..
..
- ff
..
也就是采用文件内容寻址,而非文件位置寻址的存储方式。之所以能采用这种存储方式,是因为 NPM 包一经发布内容就不会再改变,因此适合内容寻址这种内容固定的场景,同时内容寻址也忽略了包的结构关系,当一个新包下载下来解压后,遇到相同文件 Hash 值时就可以抛弃,仅存储 Hash 值不存在的文件,这样就自然实现了开头说的,pnpm 对于同一个包不同的版本也仅存储其增量改动的能力。
另一个遗留问题
但其苛刻的包管理逻辑,使我们单独使用 pnpm 管理大型 Monorepo 时容易遇到一些符合逻辑但又觉得别扭的地方,比如如果每个 Package 对于同一个包的引用版本产生了分化,可能会导致 Peer Deps 了这些包的包产生多份实例,而这些包版本的分化可能是不小心导致的,我们可能需要使用 Rush 等 Monorepo 管理工具来保证版本的一致性。