Vite 相关
vite 可以类比成 webpack+webpack-dev-server,特点是:
- 快速的冷启动
- 即时的模块热更新(HMR)
- 按需编译 vite 会直接启动开发服务器,而 webpack 需要构建依赖图等等,将所有代码打包到一起,再放到开发服务器上运行。 主要区别在开发阶段,生产阶段的区别主要是 Rollup 和 Webpack 的区别
开发阶段
冷启动
- Webpack:启动时执行 webpack 打包命令,将所有模块的依赖都打包到一起放到服务器上运行
- Vite:快速冷启动,只启动一个开发服务器。遇到模块时作为单独的 HTTP 请求向开发服务器请求,开发服务器编译,加载相关依赖后返回
HMR
- Webpack:重新编译被改动的模块的所有相关依赖模块
- Vite:重新请求被改动的模块
生态
- Webpack:生态更成熟,plugins 更多
- Vite:还比较年轻
打包工具
- Webpack:适合开发应用,对于 CommonJS,AMD,ES Module 语法都兼容
- Rollup:适合开发类库,只支持 ES Module
esbuild 依赖预构建
什么是依赖预构建 (类似于打包构建,但是没有组合
-
首次启动的时候 Vite 默认情况下,Vite 会抓取你的 index.html 来检测需��要预构建的依赖项,将 HTML 文件作为应用入口(也可以通过 optimizeDeps.entries 属性自定义入口)
-
然后根据入口文件扫描出(由 scanImports 函数完成,/packages/vite/src/node/optimizer/scan.ts)项目中用到的第三方依赖
-
最后对这些依赖逐个进行编译,最后将编译后的文件缓存在内存中(node_modules/.vite 文件下),在启动 DevServer 时(启动时而不是打开页面时)直接请求该缓存内容。
.png)
- 但是,vite 的扫描并不是百分之百准确的,比如在某些动态 import 的场景下,由于 Vite 天然按需加载的特性,经常会导致某些依赖只能在运行时被识别出来。
在 vite.config.js 文件中配置 optimizeDeps optimizeDeps.include:string 或者 optimizeDeps.exclude:string 选项可以选择需要或不需要进行预编译的依赖的名称
Vite 则会根据该选项来确定是否对该依赖进行预编译。如果依赖项很大(包含很多内部模块)或者是 CommonJS,那么你应该包含它;因为 commonjs 需要被处理成 esm,会消耗时间,既然我们可以提前编译,就应该预编译它
如果依赖项很小,并且已经是有效的 ESM,则可以排除它,让浏览器直接加载它(不需要放入预构建的缓存里,浏览器启动后才去加载)。(性能优化思路)
- 在启动时添加 --force options,可以用来强制重新(强制重新依赖预构建指的是忽略之前已构建的文件,直接重新编译)进行依赖预构建。
依赖预构建的另一作用:整合代码
-
兼容 CommonJS 和 AMD 模块的依赖:因为 Vite 的 DevServer 是基于浏览器的 Natvie ES Module 实现的,所以对于使用的依赖如果是 CommonJS 或 AMD 的模块(必须经过构建,转换语法),则需要进行模块类型的转化(ES Module)。
-
减少模块间依赖引用导致过多的请求次数(预构建的内容,不需要在浏览器页面启动后再去请求 esm 模块):通常我们引入的一些依赖,它自己又会一些其他依赖。
官方示例
一些包将它们的 ES 模块构建作为许多单独的文件相互导入。例如,lodash-es 内部有超过 600 多个模块。当我们执行
import { debounce } from 'lodash-es' 时,浏览器同时发出 600 多个 HTTP 请求!尽管服务器在处理这些请
求时没有问题,但大量的请求会在浏览器端造成网络拥塞,导致页面的加载速度相当慢。
lodash-es 模块使用预编译相较于未使用预编译请求加载速度缩短了近 20 倍的时间!
经过预构建后相当于把含 600 个引用的模块编译为一个文件,同时不会产生复杂的相对路径
依赖预构建的源码实现
所有的预构建产物默认缓存在 node_modules/.vite 目录中。如果以下 3 个地方都没有改动,Vite 将一直��使用缓存文件:
- package.json 的 dependencies 字段
- 各种包管理器的 lockfile 文件
- vite --force / 直接删掉 .vite 目录
.png)
通过 bind 方法重写 listen 函数
httpserver 是 node 模块上带的创建服务器方法
这里用了去除 listen,绑定 this,扩展重写的技巧
在执行 yarn dev 启动 DevServer 之前,vite 会拦截通过重写 listen 函数调用 runOptimize 函数,进行依赖预构建相关的处理
runOptimize 函数负责的是调用和注册处理依赖预构建相关的函数,该函数主要完成两件事。
第一件事:进行依赖预构建 optimizeDeps()
optimizeDeps()主要是根据配置文件生成 hash,获取上次预购建的内容(存放在_metadata.json 文件)。如果不是强预构建就对比_metadata.json 文件的 hash 和新生成的 hash:一致就返回_metadata.json 文件的内容,否则清空缓存文件通过 ScanImport 调用 Esbuild 构建模块再次存入_metadata.json 文件
optimizeDps 函数: ● 根据 --force 参数判断是否是强预构建 ● 如果不是强预构建,则对比对比缓存文件__metadata.json 的 hash。 ● 缓存失效或者未缓存则根据 optimizeDps 配置使用 esbuild 编译依赖。
.png)
四个属性
● hash 由需要进行预编译的文件内容生成的,用于防止 DevServer 启动时重复编译相同的依赖,即依赖并没有发生变化,不需要重新编译。
● browserHash 由 hash 和在运行时发现的额外的依赖生成的,用于让预编译的依赖的浏览器请求无效。
● optimized 包含每个进行过预编译的依赖,其对应的属性会描述依赖源文件路径 src 和编译后所在路径 file。
● needsInterop 主要用于在 Vite 进行依赖性导入分析,这是由 importAnalysisPlugin 插件中的 transformCjsImport 函数负责的,它会对需要预编译且为 CommonJS 的依赖导入代码进行重写。
第二件事:注册依赖预构建相关函数 createMissingImporterRegisterFn()
调用 createMissingImpoterRegisterFn 函数,它会返回一个函数,其仍然内部会调用 optimizeDeps 函数进行预编译
只是不同于第一次预编译过程,此时会传入一个 newDeps,即新的需要进行预编译的依赖。
在服务器已经启动之后,如果遇到一个新的依赖关系导入,而这个依赖关系还没有在缓存中,Vite 将重新运行依赖构建进程并重新加载页面。
.png)
二次预构建
注意这并不属于 HMR, 而是依赖关系(如 package.json 改变)改变触发,重新编译需要进行预编译的依赖
为什么选 vite
在浏览器支持 ES 模块之前,JavaScript 并没有提供原生机制让开发者以模块化的方式进行开发。这也正是我们对 “打包” 这个概念熟悉的原因:使用工具抓取、处理并将我们的源码模块串联成可以在浏览器中运行的文件。
时过境迁,我们见证了诸如 webpack、Rollup 和 Parcel 等工具的变迁,它们极大地改善了前端开发者的开发体验。
然而,当我们开始构建越来越大型的应用时,需要处理的 JavaScript 代码量也呈指数级增长。包含数千个模块的大型项目相当普遍。基于 JavaScript 开发的工具就会开始遇到性能瓶颈:通常需要很长时间(甚至是几分钟!)才能启动开发服务器,即使使用模块热替换(HMR),文件修改后的效果也需要几秒钟才能在浏览器中反映出来。如此循环往复,迟钝的反馈会极大地影响开发者的开发效率和幸福感。
Vite 旨在利用生态系统中的新进展解决上述问题:浏览器开始原生支持 ES 模块,且越来越多 JavaScript 工具使用编译型语言编写。
缓慢的服务器启动
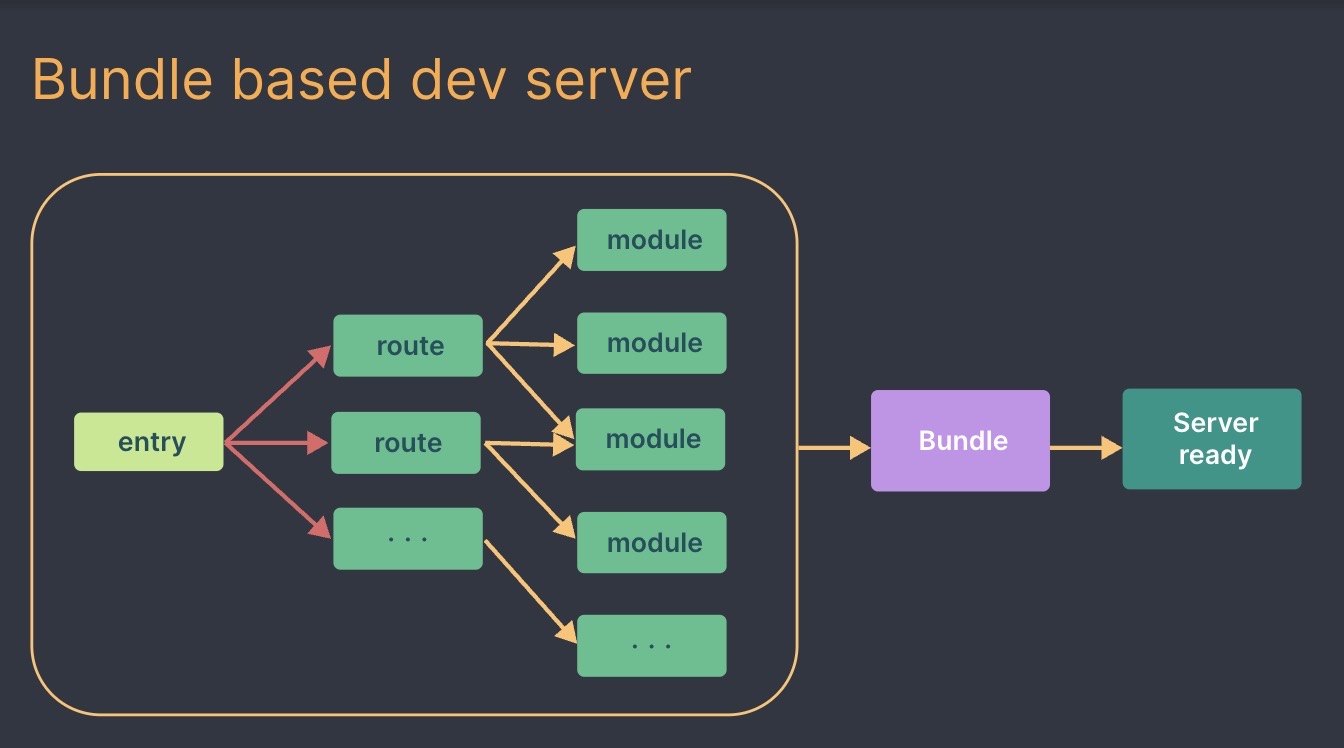
当冷启动开发服务器时,基于打包器的方式启动必须优先抓取并构建你的整个应用,然后才能提供服务。
Vite 通过在一开始将应用中的模块区分为 依赖 和 源码 两类,改进了开发服务器启动时间。
依赖 大多为在开发时不会变动的纯 JavaScript。一些较大的依赖(例如有上百个模块的组件库)处理的代价也很高。依赖也通常会存在多种模块化格式(例如 ESM 或者 CommonJS)。
Vite 将会使用 esbuild 预构建依赖。esbuild 使用 Go 编写,并且比以 JavaScript 编写的打包器预构建依赖快 10-100 倍。
源码 通常包含一些并非直接是 JavaScript 的文件,需要转换(例如 JSX,CSS 或者 Vue/Svelte 组件),时常会被编辑。同时,并不是所有的源码都需要同时被加载(例如基于路由拆分的代码模块)可以分包或动态 import。
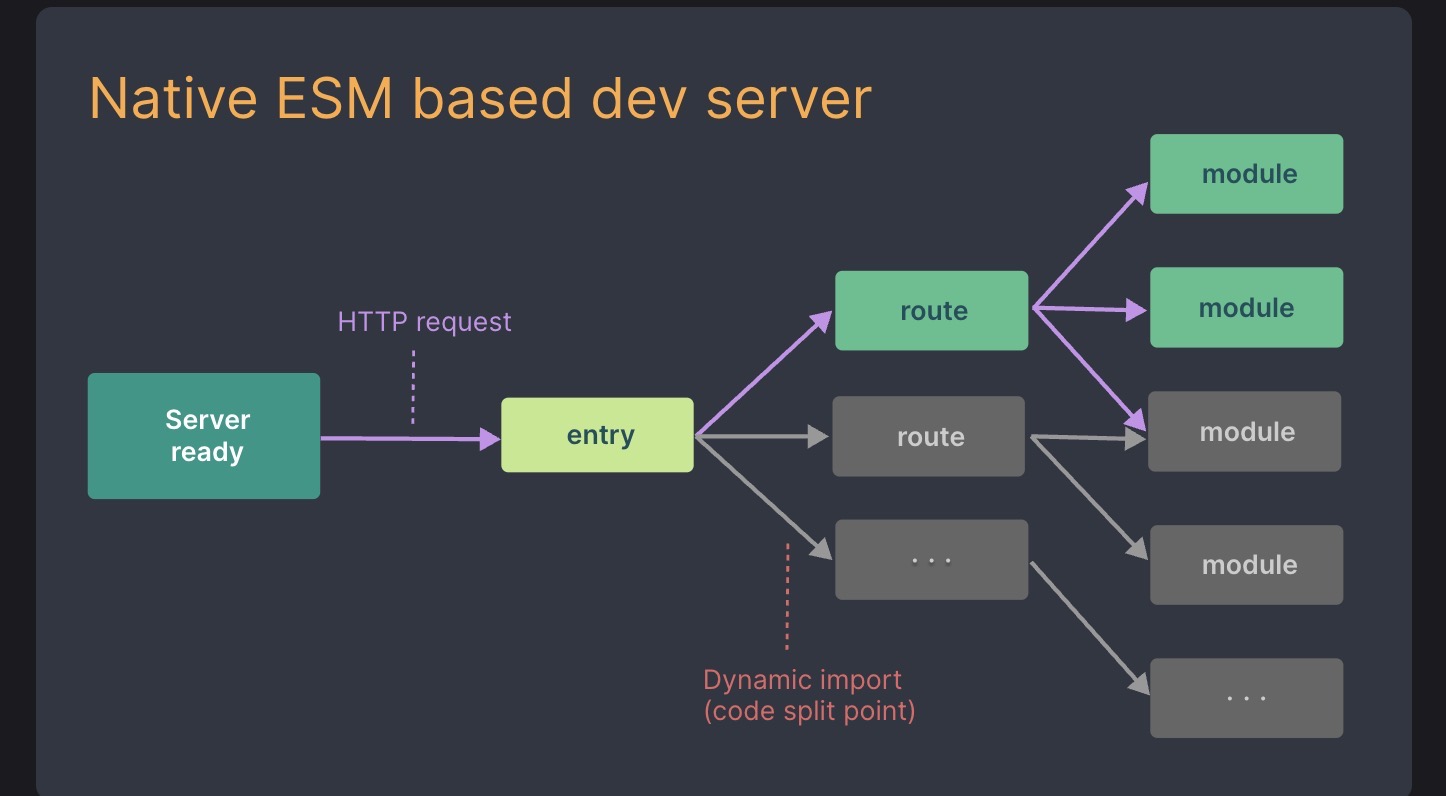
Vite 以 原生 ESM 方式提供源码。这实际上是让浏览器接管了打包程序的部分工作:Vite 只需要在浏览器请求源码时进行转换并按需提供源码。根据情景动态导入代码,即只在当前屏幕上实际使用时才会被处理
传统构建
基于 ESM 原生构建
缓慢的更新
基于打包器启动时,重建整个包的效率很低。原因显而易见:因为这样更新速度会随着应用体积增长而直线下降。
一些打包器的开发服务器将构建内容存入内存,这样它们只需要在文件更改时使模块图的一部分失活[1],但它也��仍需要整个重新构建并重载页面。这样代价很高,并且重新加载页面会消除应用的当前状态,所以打包器支持了动态模块热替换(HMR):允许一个模块 “热替换” 它自己,而不会影响页面其余部分。这大大改进了开发体验 —— 然而,在实践中我们发现,即使采用了 HMR 模式,其热更新速度也会随着应用规模的增长而显著下降。
在 Vite 中,HMR 是在原生 ESM 上执行的。当编辑一个文件时,Vite 只需要精确地使已编辑的模块与其最近的 HMR 边界之间的链失活[1](大多数时候只是模块本身),使得无论应用大小如何,HMR 始终能保持快速更新。
Vite 同时利用 HTTP 头来加速整个页面的重新加载(再次让浏览器为我们做更多事情):源码模块的请求会根据 304 Not Modified 进行协商缓存,
而依赖模块请求则会通过 Cache-Control: max-age=31536000,immutable 进行强缓存,因此一旦被缓存它们将不需要再次请求。
通过请求导入 ESM 模块
尽管依赖模块可以被缓存,但是在首次构建的情况下
vite 会解析每个 js 文件的 import 语句,生成标注 type:module 的浏览器 script,因此会发送大量请求,尤其是在嵌套导入的情况下,带来额外的网络往返,降低了效率
为什么生产环境仍需打包
尽管原生 ESM ��现在得到了广泛支持,但由于嵌套导入会导致额外的网络往返,在生产环境中发布未打包的 ESM 仍然效率低下(即使使用 HTTP/2)。为了在生产环境中获得最佳的加载性能,最好还是将代码进行 tree-shaking、懒加载和 chunk 分割(以获得更好的缓存)。
要确保开发服务器和生产环境构建之间的最优输出和行为一致并不容易。所以 Vite 附带了一套 构建优化 的 构建命令,开箱即用。
为何不用 ESBuild 打包?
Vite 目前的插件 API 与使用 esbuild 作为打包器并不兼容。尽管 esbuild 速度更快,但 Vite 采用了 Rollup 灵活的插件 API 和基础建设,这对 Vite 在生态中的成功起到了重要作用。目前来看,我们认为 Rollup 提供了更好的性能与灵活性方面的权衡。
Rollup 已经开始着手改进性能,在 v4 中将其解析器切换到 SWC。同时还有一个正在进行中的工作,即构建一个名为 Rolldown 的 Rust 版本的 Rollup。一旦 Rolldown 准备就绪,它就可以在 Vite 中取代 Rollup 和 esbuild,显著提高构建性能,并消除开发和构建之间的不一致性。